Olen tehnyt NLP-ratkaisuja nyt 15 vuotta. ChatGPT:n ja muiden suurten kielimallien johdosta kaikki tietävät mitä NLP on, mutta kirjoitan tässä mitä ja millaista se oli ennen LLM-aikakautta. "Elettiin sitä ennenkin"-osastoa, mutta toivottavasti pidät kirjoitusta kiinnostavana.
Mitä ovat NLP-ongelmat?
Nykyään näkee pääasiassa generatiivista tekoälyä: ratkaisu tuottaa tekstiä/puhetta/kuvia/videoita tai sitten se suorittaa pieniä toimenpiteitä, jos se on agentti ja sillä on käytössään työkaluja. Ja ilman muuta sen kanssa voi asioida kirjoittamalla tai puhumalla ihan tavallista kieltä.
Ennen kuin oli suuria kielimalleja, jotka ymmärtävät ja kykenevät generoimaan kieltä tarpeeksi hyvällä laadulla, piti tähdätä pienempiin tavoitteisiin. Tavoite saattoi olla esimerkiksi:
- tekstin luokittelu (spam-viesti, laskutusviesti, valitus, jne ...),
- tekstin sävyn tunnistaminen (positiivinen, negatiivinen, neutraali),
- samanlaisten tekstien suositteleminen ("lue lisää aiheesta ..."),
- entiteettien (eli henkilöiden, paikkojen, jne ...) löytäminen tekstistä,
- tekstien ryhmittely (klusterointi) tai
- tulevan ennustaminen ('seuraava sana on "sinua"').
Suosittelua ontologiamoottorilla
2010 astuin Leiki Oy:n palvelukseen ja Leiki Oy:n pääasiallinen tuote oli suosittelu. Esimerkiksi verkkolehden sivustolla on juttu, jonka viereen ratkaisu keksi lisää artikkeleita samasta aiheesta tai aiheen vierestä.
Leiki Oy:n suositusmoottori toimi ontologian perusteella. Ja ontologia on käsitteiden ja niiden välisten suhteiden kokoelma, jota yritän tässä kuvata vertaamalla niitä Wikipediaan: Wikipediassa jokaisella käsitteellä on se oma sivunsa (jonka käyttäjä lukee) mutta sen lisäksi siellä on käsitteen asiasanoja sekä linkkejä ylä- ja alakäsitteisiin. Ja niinpä voidaan sanoa, että tietyt sanat liittyvät tiettyyn käsitteeseen ja että se käsite on lähellä tai kaukana jostakin toisesta käsitteestä.
Leiki Oy:n ratkaisu pystyi analysoimaan tekstejä (mitä sanoja ja vastaavasti käsitteitä siinä on) ja etsimään artikkelikannasta läheisiä artikkeleja. Teknisesti ottaen käytössä oli regex (artikkelin aiheiden tunnistaminen) ja vektorihaku (samankaltaisten artikkelien haku) sekä erilaisia hakukonetekniikoita kuten erilaiset indeksointi-, normalisointi- ja disambiguaatioalgoritmit. Suosittelun lisäksi työskentelimme myös luokittelu-, sävyntunnistuksen- ja entiteettihaun ongelmien parissa.
Ontologian käyttäminen tekstin analyysiin oli Leikin erikoisyys. Vektorihakuteknologiat olivat jo yleisessä tiedossa mutta tekstin muuntaminen vektorimuotoon siten, että vektoriesitys on millään tavalla käyttökelpoinen, siihen ei ollut yleismaailmallisesti tunnistettuja ja hyväksi havaittuja menetelmiä.
Orastavaa koneoppimista ja tilastollisia menetelmiä
Siihen aikaan NLP:n koneoppimis- ja tilastolliset menetelmät olivat melko vaatimattomia. Jos ei käytetty ontologioihin pohjaavia menetelmiä, niin sanasto saatettiin esimerkiksi muuntaa one-hot -vektoreiksi tai käyttää tekstin muita piirteitä. Esimerkiksi, jos viestissä on paljon huutomerkkejä, isoja kirjaimia ja sanoja kuten "RAHA" ja "RIKAS", niin se on kohtuullisen hyvä merkki siitä, että kyseessä mahdollisesti on SPAM-viesti.
Word2Vec vuodelta 2013 oli ensimmäinen kerta, kun minusta tuntui siltä, että kielen ilmiöt avautuivat koneoppimismenetelmille. Word2Vecissä koulutetaan sanavektoreita sanojen yhteisesiintymisen perusteella ja näillä vektoreilla on mm. sellainen mielenkiintoinen ominaisuus, että vektoriaritmeettiset operaatiot tuottavat semanttisesti mielekkäitä tuloksia. Esimerkiksi sanojen "kuningas", "mies", "kuningatar" ja "nainen" vektoreista pätee seuraava:
kuningas - mies + nainen ≈ kuningatar
Toinen samantapainen sanaupotusalgoritmi ("sanaupotus" ~ "word embedding" ~ "sanavektori") oli Glove vuodelta 2014.
Sanaupotusmenetelmien tulokset soveltuivat hyvin yhteen koneoppimismenetelmien kanssa (tai ovat koneoppimista) ja sanaupotusmalleja ja niitä hyödyntäviä verkkoja kehitettiin joka suunnalla. Pian suuret toimijat alkoivat julkaista sanaupotusmallejaan (eli malleja, jotka muuttavat tekstiä vektoreiksi) yleiseen käyttöön. Esimerkiksi Facebook julkaisi nopeat ja suurilla aineistoilla koulutetut FastText mallinsa eri kielille.
Koneoppimismenetelmiä hyödyntävät ratkaisut alkoivat samaan aikaan ilmaantua myös koteihin: älytelevisiot tuottivat ja ymmärsivät puhetta. Pian ilmestyi puhetta ymmärtäviä kodin yleisohjausjärjestelmiä kuten Alexa.
Chatbotit ennen suuria kielimalleja
Erilaiset viestialustat kuten WhatsApp ja Messenger ovat olleet kovassa huudossa jo pitkään. Vuonna 2016 työskentelin Jongla-nimisessä yrityksessä. Jongla oli viestialusta, jonka kulmana bisnekseen oli kevyt viesticlient, ja kohdemaana erityisesti kehittyvät taloudet. Pääsin tekemään Jonglalle botteja ja bottialgoritmeja.
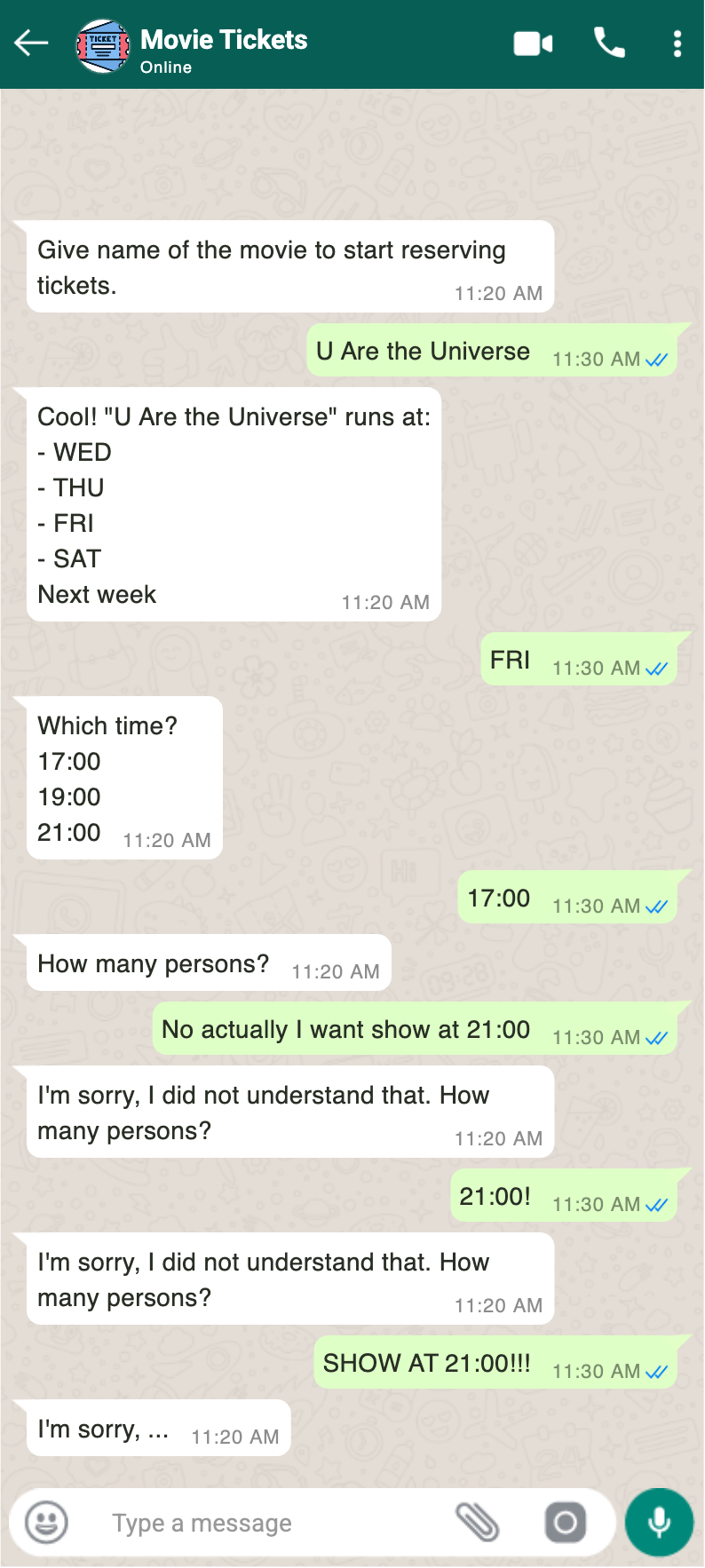
Suuria kielimalleja ei ollut vielä käytössä ja niinpä bottien kommunikaatio piti jäsentää määrämuotoisten, koneluettavien viestien kautta. Mielenkiintoinen asia bottialgoritmiikassa oli (ja on vieläkin) bottien toimintalogiikan jäsentäminen ja ohjelmointi. Iso ongelma oli se, että botit olivat tyypillisesti "kalkkeutuneita" tai "jääräpäisiä" ("recalcitrant"), koska ne toimivat jäykkien skriptien pohjalta. Viereisessä kuvassa on esimerkki siitä, millaista viestittely jääräpäisen botin kanssa on. Pienellä ylpeydellä muistelen kehittämääni tilakoneisiin ja graafeihin perustuvaa bottialgoritmia, joka kykeni ohjaamaan botin toimintaa kovakoodattujen skriptien ja kulkujen ohi silloin kun käyttäjän viestit eivät vastanneet botin odottamaa määrämuotoista vastausta.
Tällainen logiikan ohjelmointi on vieläkin tarpeellista ja ajankohtaista. Kielimallit eivät yksinään sovellu kaiken ohjaamiseen: ne ovat epädeterministisiä, hitaita, kalliita ja voivat toimia arvaamattomasti — mikä tekee puhtaasti LLM-pohjaisesta ohjauksesta turvallisuusriskin. Nyt käytössä on hienoja luonnollista kieltä ymmärtäviä malleja, mutta lisäksi tarvitaan se jokin, joka kuljettaa ratkaisua ja käyttäjää eteenpäin, tilasta toiseen. Toisinaan ratkaisun pitää osata kutsua jotakin työkalua tai vaikkapa päättää interaktio käyttäjän kanssa. Tällaista työtä tehdään edelleenkin ja LLM-kehykset kuten LangChain ja LlamaIndex pyrkivät osaltaan virtaviivaistamaan tekoälyratkaisujen tilasiirtymien logiikkaa. Myös Manus AI (nykyään Metan omistuksessa) rakensi upean itsenäisen agentin yhdistämällä kielimalleja ja algoritmiikkaa oivaltavasti.
Ensimmäinen pesti koneoppimisinsinöörinä
Sain ensimmäisen koneoppimisinsinöörin kiinnitykseni yrityksessä UltimateAI (nyttemmin "Zendesk AI Agents") vuoden 2018 lopulla. Olin opiskellut koneoppimista Courseran koneoppimiskursseilla (alla oleva meemi on varmasti tuttu Courseran koneoppimiskursseilla opiskelleille) jonkin aikaa ja minulla on hyvät pohjatiedot relevantista matematiikasta ja tilastotieteestä. Nyt myös aika sekä käytettävät menetelmät olivat riittävällä tasolla NLP-tarkoituksiin. Erona aikaisempiin työpaikkoihin olivat oikeat koneoppimismenetelmät ja datatieteellinen lähestymistapa.

Yksi tapa kuvata koneoppimista ja datatiedettä on sanoa, että se on dataohjautunutta ("data driven"). Suuret aineistot, niiden hahmottaminen ja käsittely olivat minulle tuttuja Leiki Oy:n ajoilta mutta Leikissä menetelmät aineistojen käsittelemiseen ja hahmottamiseen eivät olleet kovin formaaleja. Kaikenlainen tilastollinen ajattelu piti itse tuoda työhön. Tätä vastoin UltimateAI:ssa lähdettiin koneoppimisnatiivilta pohjalta ja niinpä aineistoihin tutustuttiin ja niitä analysoitiin tilastollisesti perustelluilla menetelmillä, jotka olivat vieläpä hioutuneet vuosien varrella paljolti siksi työkalupakiksi, jota datatieteilijät käyttävät. Pyörää ei yritetty keksiä uudelleen vaan sovellettiin yleisesti tunnettuja ja hyväksi todettuja menetelmiä.
Olin saanut hyödyntää koneoppimismenetelmiä vain kursseilla ennen aikaani UltimateAI:ssa. Ultimatessa työn ydin oli koneoppimista: verkkojen koulutusprosessin säätämistä, inferenssin säätämistä, ja AI-infrastruktuuria. Tehokkain tapa oppia uutta on päästä tekemään sitä hyvässä porukassa. UltimateAI oli loistava paikka koneoppimisen ja datatieteen oppimiseen käytännössä. Ultimate AI:ssa koulutettiin omia malleja ja hyödynnettiin ja kokeiltiin kaikkea vapaasti tarjolla olevaa: FastText-malleja ja sitten transformer-pohjaisia malleja, Universal Dependencies -kieliresursseja, ja UDPipe-malleja. Jokainen NLP-ratkaisu piti rakentaa itse: luokittelu, entiteettien eristäminen, sentimenttitunnistus jne.
Ultimaten aikana havaitsin myös huomattavan asennemuutoksen. Olin tehnyt NLP:tä vajaat kymmenen vuotta ja sinä aikana käynyt lukuisia keskusteluja. Kun ennen Ultimatea kerroin mitä teen, niin tyypillinen reaktio oli "meh", kuulijan katse alkoi harhailla kattolistoissa ja olen saanut todistaa melko mojovia haukotuspommeja. Tätä vastoin aloitettuani työt koneoppimisinsinöörinä yleinen suhtautuminen muuttui. Vanhat kaverit laittoivat viestejä, että "toi mitä sä teet on kuuminta hottia" ja uteliaita varten olisi ollut hyvä olla jonkinlainen jonotusjärjestelmä.
Aavistuksia tulevasta
Aloitan tämän kappaleen seuraavalla meemillä, jonka (tai jotakin samankaltaista) näin UltimateAI:n Slackissä joskus 2019-2020.

Ennen kuin OpenAI:n putkesta oli tullut mitään hienoa ulos, OpenAI käytti huimia summia kielimallien kouluttamiseen. Silloin ei ollut yleisessä tiedossa, että suuret kielimallit muuttaisivat maailmaa niin radikaalisti. Tietysti nykyisiin verrattuna silloiset AI-sijoitukset olivat pikkurahoja mutta sillä hetkellä ja epävarmuuden vallitessa ne olivat hämmästyttävän suuria.
Lopulta OpenAI löi suuresti läpi 2022 ChatGPT:n julkaisun jälkeen.
Muutama loppuhuomio
Asiakasta lähellä tapahtuva NLP-työ on muuttunut huimasti sen jälkeen kun suuret kielimallit tulivat. Sitä ei tehdä enää samoilla menetelmillä. Neuroverkkojen koulutus ja suuri osa luonnollisen kielen detaljien kanssa painiminen on piilotettu konepellin alle kielimallivendorien ja -kehysten tasolla. Ratkaisutarpeet tyydytetään prompttauksella ja LLM-kehyksillä.
Mielestäni titteli "koneoppimisinsinööri" on kokenut inflaation. Jos puhutaan asiakasta lähellä tapahtuvasta kehitystyöstä, niin harva "koneoppimisinsinööri" työskentelee koneoppimisen yksityiskohtien ja asioiden kanssa tai on niistä edes tietoinen. AI-insinööri on mielestäni osuvampi ilmaus.
Menetelmät ovat vaihtuneet mutta domain on sama: luonnollisen kielen käsittely tekoälyä hyödyntäen. Tällä hetkellä NLP-insinöörien työhön kuuluu kontekstin hallinta, prompttaus, ratkaisun orkestrointi, mallien valinta, guardrailing ja evaluointi. Tässä vielä havaintoja siitä miten nämä työaiheet ovat muuttuneet LLM-kaudelle tultaessa:
- aiemmin prompttaus ei ollut pääasiallinen työväline vaan pikemminkin erikoisuus, johon piti nojata toisinaan - esimerkiksi aineistoa rikastaessa tai muuten aineistoa augmentoitaessa
- orkestrointi on periaatteessa samanlaista mutta nyt käytettävissä on paljon erilaisia kehyksiä ja valmispalveluita
- ennenkin puntaroitiin sitä, mikä olisi paras tekoälymalli kuhunkin ongelmaan mutta valtaosa malleista ei ollut generatiivisia
- guardrailing oli olemassa mutta menetelmät olivat erilaisia: esimerkiksi blacklisting, syötteen ja palautteen validointi, ja filtteröinti
- evaluointi ja metriikat ovat muuttuneet täysin erilaisiksi koska generatiivisten mallien tuotokset eivät ole deterministisiä eivätkä koneluettavassa muodossa, esimerkiksi Scorable (Root Signals) tekee nimenomaan tätä
- kontekstin hallinta on ehkä melko samanlaista kuin ennen, context poisoning ja context dilution olivat juttu jo ennen LLM-aikaa - erona ehkä se, että kontekstin manipulointiin liittyvät tietoturvaongelmat ilmestyivät vasta LLM-kaudella, kun tekoäly ryhtyi ymmärtämään ja toimimaan vapaatekstin perusteella
Sellaisia ajatuksia tällä kertaa. Kiitos kiinnostuksesta ja jätä vaikka kommentti linkkarissa tai ota yhteyttä!